周彦武

明年上市的现代G90和GV80将是现代汽车L3级自动驾驶车型,当然,L3级自动驾驶是选配的。图中是测试原型车,很明显可以看到两个激光雷达。
G90自动驾驶谍照车

这是在韩国首尔拍摄到的G90自动驾驶谍照车,激光雷达似乎是后加的。
搭载激光雷达的G90谍照

标准版G90谍照

现代汽车的全球销量稳居600万辆之上,2020年销量下滑12%,但仍达635万辆,算单独厂家不算联盟的话,现代汽车销量第三,比第四名的通用汽车略高,因此现代汽车的自动驾驶还是值得一看的。
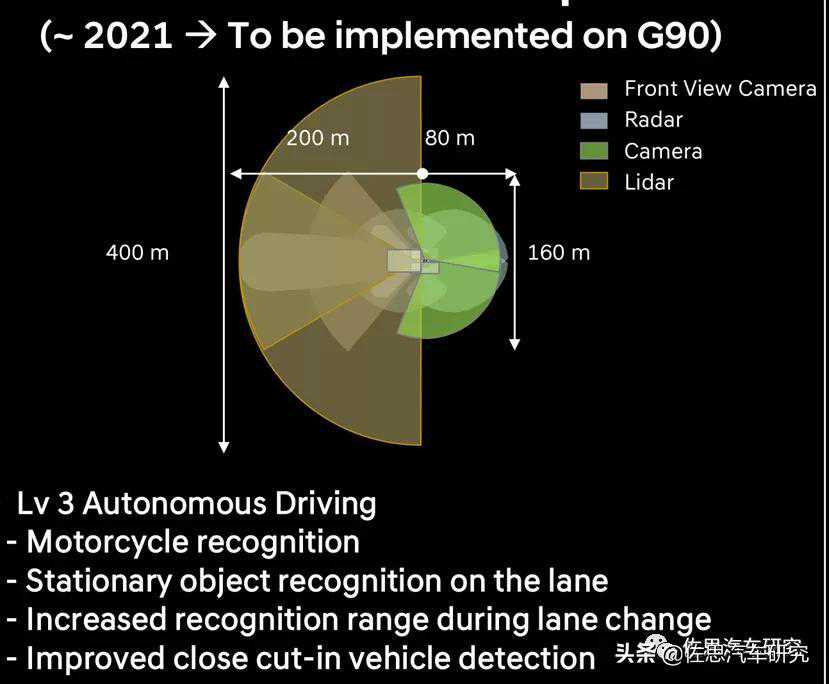
L3级自动驾驶传感器布局如上。激光雷达方面,现代汽车旗下子公司现代摩比斯曾经5千万美元投资老牌激光雷达公司Velodyne,并且与Velodyne研发量产低价激光雷达,现代摩比斯代工Velodyne的激光雷达,但比较遥远,现代汽车没有选择Velodyne的激光雷达,而是选择更老的法雷奥激光雷达,即二代Scala。
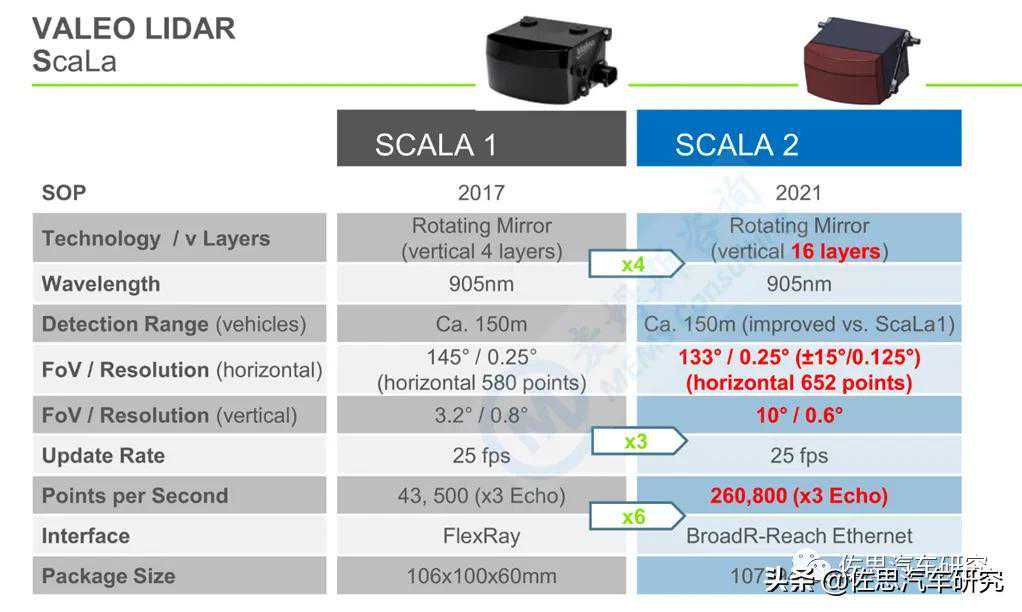
更详细的参数如下。

有效距离的参数尤其精密,不像大多数厂家简单说一个几百米,没有限定条件的参数毫无意义。在正前方,扫描密度有所增加,特别为双激光雷达设计。
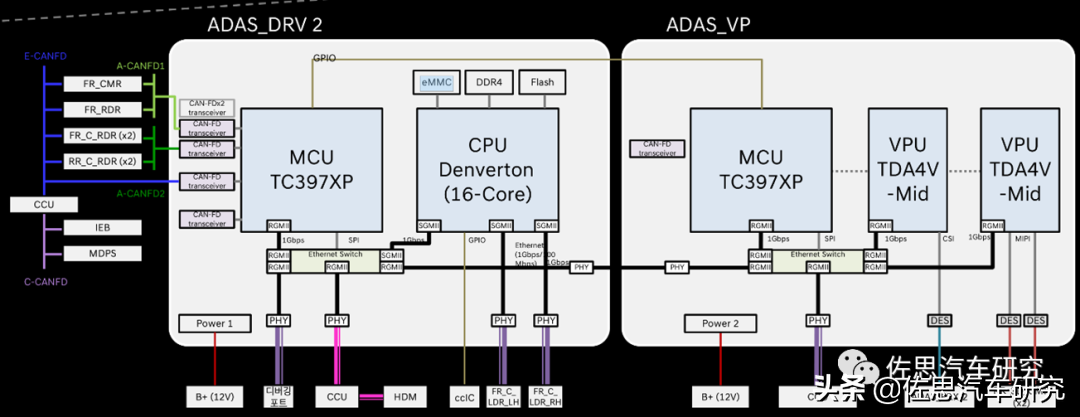
L3系统计算架构如上图。与大多数厂家不同,现代的方案力求低成本,连前视摄像头FRCMR居然用CAN-FD总线连接,而不是常见的以太网或SerDes,因此像素必然很低,估计不超过150万像素。FRRDR是前主毫米波雷达,FRCRDR和RRCRDR是4个角毫米波雷达。FRCLDRLH为左激光雷达,FRCLDRRH为右激光雷达。CCIC是中控与仪表一体的座舱显示屏,CCU实际是TCU,做OTA升级的。用韩文标注的那个是debug用的,量产时不存在。PHY是物理层芯片,大概率会是Marvell的88Q211,使用了7个PHY,大概要105-140美元。两个以太网交换机,大概率会是Marvell的88Q5050。MCU是英飞凌的TC397XP,目前缺货严重。
尽管是L3,仍然是双系统设计,且有两套供电系统。如果换了其他厂家肯定会说是L4。右侧的方框是主系统,左侧的是紧急备份系统。实际上是三套,还有一套自动泊车。这套系统应该是现代和Aptiv合资的Motional设计并生产的。

先看备份系统,CPU是英特尔的Denverton,也就是AtomC3000系列,C3000系列只有三款是16核,即C3950、C3955和C3958。其中C3950的TDP功率最低,只有24瓦,C3958是31瓦,C3955是32瓦,现代大概率会选择C3958。C3000系列主要面向IoT领域,不是针对汽车领域,而针对汽车领域的是A3900系列。不过两者应该高度相似,均属于Atom3000系列。与A3900系列不同,C3000系列不带GPU,只有CPU。C3950目前零售价大约160美元,大量采购估计在100美元左右。
4核@2.0GHz的A3950的CPU算力为42160DMIPS,C3958是16核@2.0GHz,算力应该为168.6K,大致略高于高通5纳米的SA8295,不过C3958是14纳米。此外X86的乱序执行能力比ARM要高不少,虽然DMIPS相当,但实际表现上X86很多时候都会比较好。宝马的L3系统也是选择了Denverton,估计也是16核,在传统激光雷达ICP算法中,主要靠CPU出力,这或许是为什么选择Denverton的原因。
主系统的核心元件是德州仪器的TDA4VMID,这是德州仪器针对ADAS和自动泊车推出的芯片,目前量产的仅一款即TDA4VMID,还有两款在2022年上半年有样片,一款是TDA4VMIDPlus,一款是TDA4VLow。一片算力不够的话,可以4片并联。
2022年德州仪器还有一款TDA4AH提供样片,这是德州仪器的旗舰芯片,采用8个A72@2.4GHz,算力达100KDMIPS,4个MMA,算力为36TOPS@INT8,4个C7xDSP,算力为320GFLOPS。
TDA4VMID内部框架图
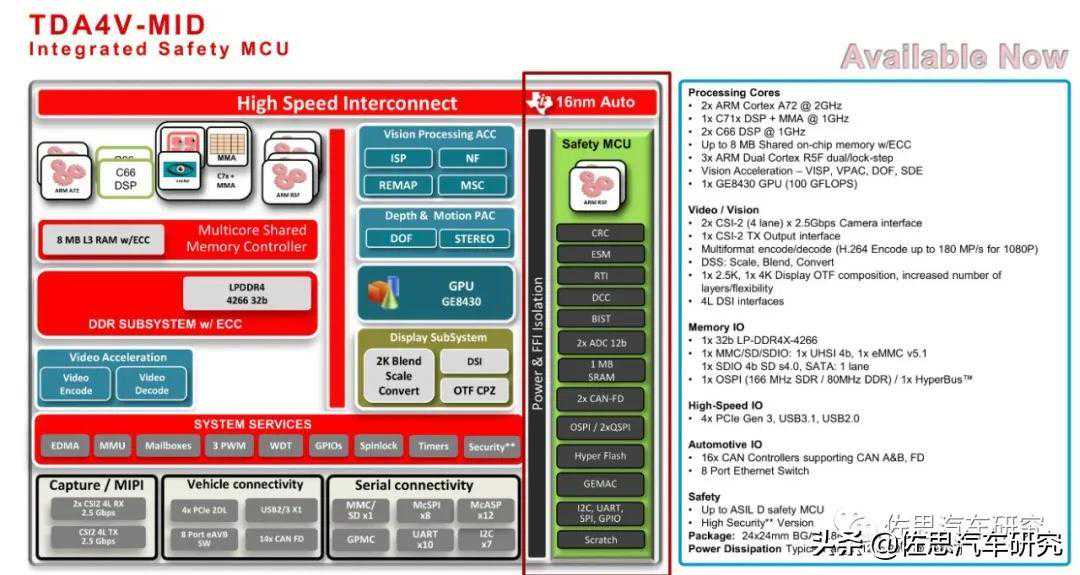
TDA4VMID采用两个A72,算力大约25KDMIPS,1个MMA,算力为8TOPS,1个C7xDSP,算力80GFLOPS,1个GE8430,算力100GFLOPS。从板子看现代L3应该是采用了4片TDA4VMID,总CPU算力有100K,NPU有32TOPS,也算不错了。
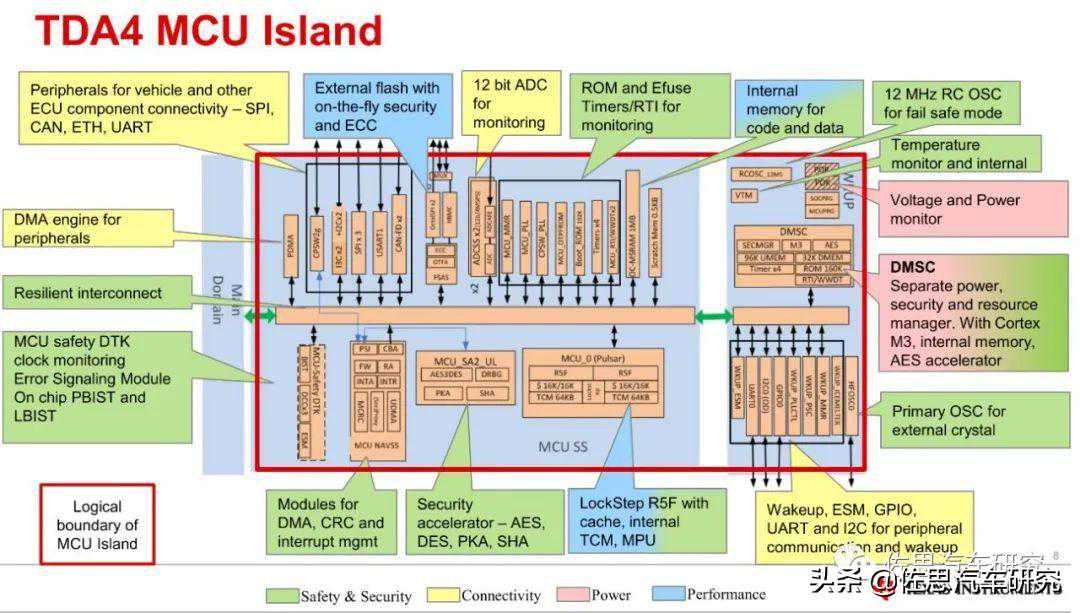
3个ARMCortex-R5F实时锁步系统,让整体芯片达到ASIL-D级。
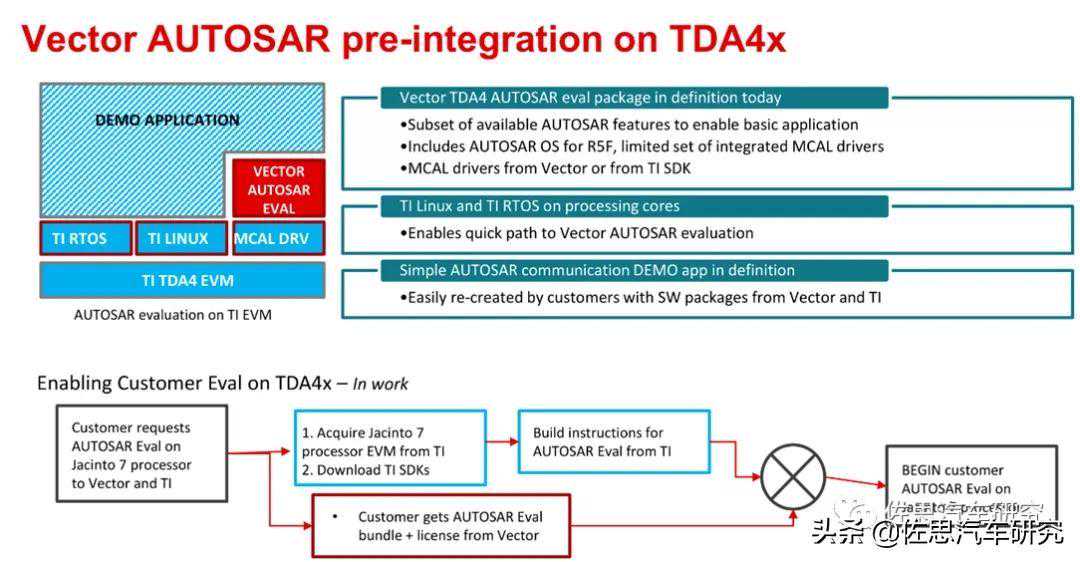
预装与底层抽象层MCAL关联的Autosar驱动,由Vector开发。
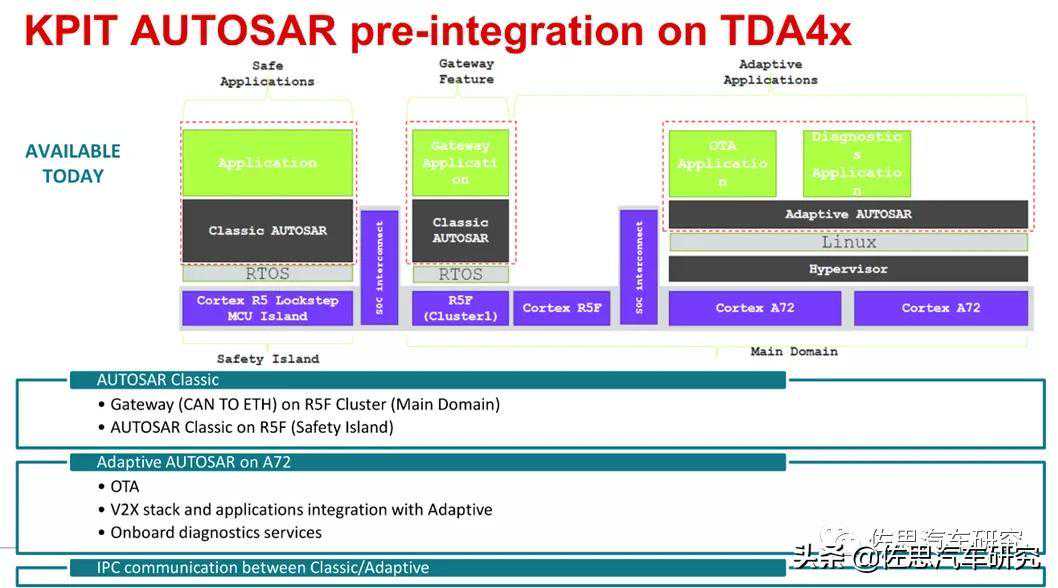
预装KPIT开发的AUTOSAR,包括网关、安全岛、OTA、V2X、诊断、IPC通讯。
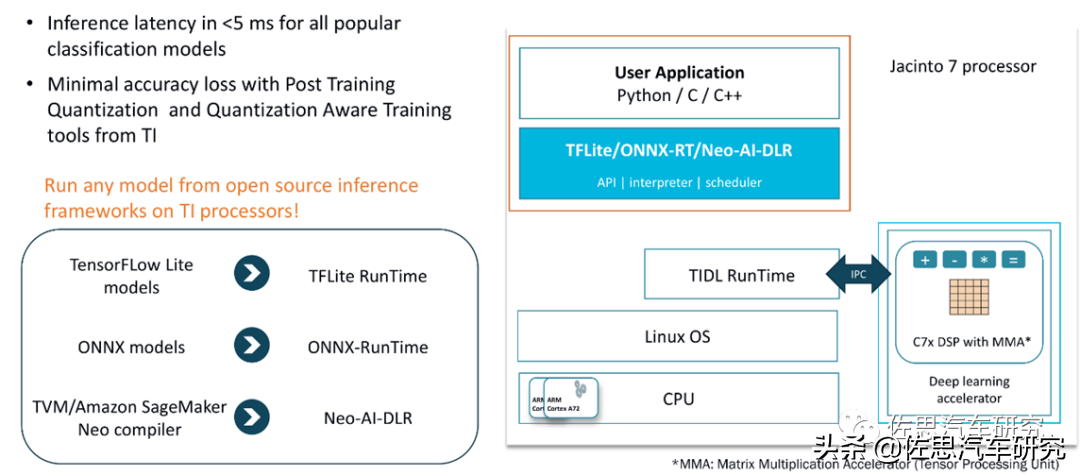
深度学习方面,德州仪器开发了TIDeepLearning(TIDL),对三大推理深度学习模型都做了优化,尤其是微软的开放式神经网络交换ONNX。硬件方面,DSP增加了MMA即矩阵乘法加速器。
DSP在深度学习方面有一个NPU之类加速器无法比拟的优势,那就是DSP采用了哈佛结构,将存储器空间划分成两个,分别存储指令和数据。它们有两组总线连接到处理器核,允许同时对它们进行访问,每个存储器独立编址,独立访问。这种安排将处理器的数据吞吐率加倍,更重要的是同时为处理器核提供数据与指令。
在这种布局下,DSP得以实现单周期的MAC指令。除DSP外的包括NPU一般都采用冯诺依曼架构,数据和程序共用总线和存储空间,在深度学习推理的卷积运算中,一条指令同时取两个操作数,在流水线处理时,同时还有一个取指操作,如果程序和数据通过一条总线访问,取指和取数必会产生冲突,而这对大运算量的循环的执行效率是很不利的。
哈佛结构能基本上解决取指和取数的冲突问题。它没有存储的瓶颈,并且是天生的流水线架构。最终的结果是DSP的深度学习推理加速算力值是几乎不含水分的,而NPU专用的深度学习推理加速表现不稳定,需要高度定制化,软硬一体,在针对其架构开发的某个模型上,加速器的利用率有90%,但是换一个模型,可能只有10%或5%,例如英伟达的Orin,其理想算力如果是254TOPS,但在某些模型上,算力会下降到12.7TOPS。实际考虑到存储瓶颈,没有一个冯诺依曼架构的加速器能达到理想值的80%。DSP的通用性强,任何模型都有90%的利用率。
现代的L3系统不依赖深度学习算力,更多依赖CPU和传统可确定可解释算法,可靠性远比依赖深度学习这种不确定不可解释算法的自动驾驶系统要高得多。
TDAV4MID的视觉加速管线
更多佐思报告
佐思2021年研究报告撰写计划
智能网联汽车产业链全景图(2021年9月版)主机厂自动驾驶
汽车视觉(上)
高精度地图
商用车自动驾驶
汽车视觉(下)
高精度定位
低速自动驾驶
汽车仿真(上)
OEM信息安全
ADAS与自动驾驶Tier1
汽车仿真(下)
汽车网关
汽车与域控制器
毫米波雷达
APA与AVP
域控制器排名分析
车用激光雷达
驾驶员监测
激光和毫米波雷达排名
车用超声波雷达
红外夜视
E/E架构
Radar拆解
车载语音
汽车分时租赁
充电基础设施
人机交互
共享出行及自动驾驶
汽车电机控制器
L4自动驾驶
EV热管理系统
混合动力报告
L2自动驾驶
汽车功率电子
汽车PCB研究
燃料电池
无线通讯模组
汽车IGBT
汽车操作系统
汽车5G
汽车线束
线控底盘
合资品牌车联网
V2X和车路协同
转向系统
自主品牌车联网
路侧智能感知
模块化报告
商用车车联网
汽车智能座舱
车载显示
商用车ADAS
座舱多屏与联屏
智能后视镜
Tier1智能座舱(上)
智能座舱设计
汽车照明
Tier1智能座舱(下)
座舱SOC
汽车座椅
汽车数字钥匙
TSP厂商及产品
HUD行业研究
汽车云服务平台
OTA研究
汽车MCU研究
AUTOSAR软件
智慧停车研究
传感器芯片
软件定义汽车
Waymo智能网联布局
ADAS/AD主控芯片
T-Box市场研究
自动驾驶法规
ADAS数据年报
T-Box排名分析
智能网联和自动驾驶基地
汽车镁合金压铸
智能汽车个性化
飞行汽车
专用车自动驾驶
农机自动驾驶
矿山自动驾驶
港口自动驾驶
自动驾驶重卡
无人接驳车
汽车VCU研究
汽车多模态交互
「佐思研究月报」
ADAS/智能汽车月报|汽车座舱电子月报|汽车视觉和汽车雷达月报|电池、电机、电控月报|车载信息系统月报|乘用车ACC数据月报|前视数据月报|HUD月报|AEB月报|APA数据月报|LKS数据月报|前雷达数据月报









