序列化参数有枚举属性,序列化端增加一个枚举,能否正常反序列化?
序列化子类,它和父类有同名参数,反序列化时,同名参数能否能正常赋值?
序列化对象增加参数,反序列化类不增加参数,能否正常反序列化?
用于序列化传输的属性,用包装器比较好,还是基本类型比较好?
为什么要使用序列化和反序列化1.程序在运行过程中,产生的数据,不能一直保存在内存中,需要暂时或永久存储到介质(如磁盘、数据库、文件)里进行保存,也可能通过网络发送给协作者。程序获取原数据,需要从介质,或网络传输获得。传输的过程中,只能使用二进制流进行传输。
2.简单的场景,基本类型数据传输。通过双方约定好参数类型,数据接收方按照既定规则对二进制流进行反序列化。
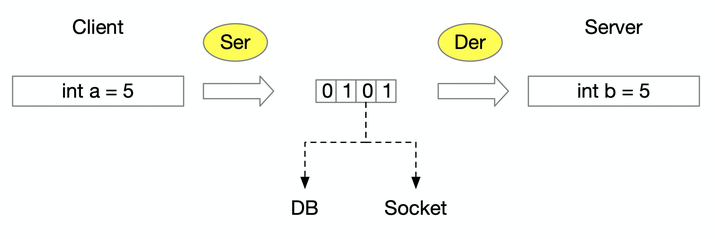
3.复杂的场景,传输数据的参数类型可能包括:基本类型、包装器类型、自定义类、枚举、时间类型、字符串、容器等。很难简单通过约定来反序列化二进制流。需要一个通用的协议,共双方使用,进行序列化和反序列化。
三种序列化协议及对比序列化协议
特点
jdk
(jdk自带)
1.序列化:除了static、transient类型
2.特点:强类型,安全性高,序列化结果携带类型信息
3.反序列化:基于Field机制
4.应用场景:深拷贝
fastjson
(第三方实现)
1.可读性好,空间占用小
2.特点:弱类型,序列化结果不携带类型信息,可读性强。有一些安全性问题
3.反序列化:基于Field机制,兼容Bean机制
4.应用场景:消息、透传对象
hessian
(第三方实现)
1.序列化:除了static、transient类型
2.特点:强类型,体积小,可跨语言,序列化结果携带类型信息
3.反序列化:基于Field机制,兼容Bean机制
4.应用场景:RPC
Fatherfather=newFather();="厨师";="川菜馆";=1;=newInteger(10);=1;=newDouble(10);=newBigDecimal(11.5);运行结果:
jdk序列化结果长度:626,耗时:55jdk反序列化结果:Father{version=0,name='厨师',comment='川菜馆',boxInt=10,simpleInt=1,boxDouble=10.0,simpleDouble=1.0,bigDecimal=11.5}耗时:87hessian序列化结果长度:182,耗时:56hessian反序列化结果:Father{version=0,name='厨师',comment='川菜馆',boxInt=10,simpleInt=1,boxDouble=10.0,simpleDouble=1.0,bigDecimal=11.5}耗时:7Fastjson序列化结果长度:119,耗时:225Fastjson反序列化结果:Father{version=0,name='厨师',comment='川菜馆',boxInt=10,simpleInt=1,boxDouble=10.0,simpleDouble=1.0,bigDecimal=11.5}耗时:69分析:jdk序列化耗时最短,但是序列化结果长度最长,是其它两种的3~5倍。
fastjson序列化结果长度最短,但是耗时是其它两种的4倍左右。
hessian序列化耗时与jdk差别不大,远小于fastjson序列化耗时。且与jdk相比,序列化结果占用空间非常有优势。另外,hessian的反序列化速度最快,耗时是其它两种的1/10。
综上比较,hessian在序列化和反序列化表现中,性能最优。
Hessian序列化实战实验准备父类publicclassFatherimplementsSerializable{/***静态类型不会被序列化*/privatestaticfinallongserialVersionUID=1L;/***transient不会被序列化*/transientintversion=0;/***名称*/publicStringname;/***备注*/publicStringcomment;/***包装器类型1*/publicIntegerboxInt;/***基本类型1*/publicintsimpleInt;/***包装器类型2*/publicDoubleboxDouble;/***基本类型2*/publicdoublesimpleDouble;/***BigDecimal*/publicBigDecimalbigDecimal;publicFather(){}@OverridepublicStringtoString(){return"Father{"+"version="+version+",name='"+name+'\''+",comment='"+comment+'\''+",boxInt="+boxInt+",simpleInt="+simpleInt+",boxDouble="+boxDouble+",simpleDouble="+simpleDouble+",bigDecimal="+bigDecimal+'}';}}子类publicclassSonextsFather{/***名称,与father同名属性*/publicStringname;/***自定义类*/publicAttributesattributes;/***枚举*/publicColorcolor;publicSon(){}}属性-自定义类publicclassAttributesimplementsSerializable{privatestaticfinallongserialVersionUID=1L;publicintvalue;publicStringmsg;publicAttributes(){}publicAttributes(intvalue,Stringmsg){=value;=msg;}}枚举publicenumColor{RED(1,"red"),YELLOW(2,"yellow");publicintvalue;publicStringmsg;Color(){}Color(intvalue,Stringmsg){=value;=msg;}}使用到的对象及属性设置
Sonson=newSon();="厨师";//父子类同名字段,只给子类属性赋值="川菜馆";=1;=newInteger(10);=1;=newDouble(10);=newBigDecimal(11.5);=;=newAttributes(11,"hello");运行结果分析
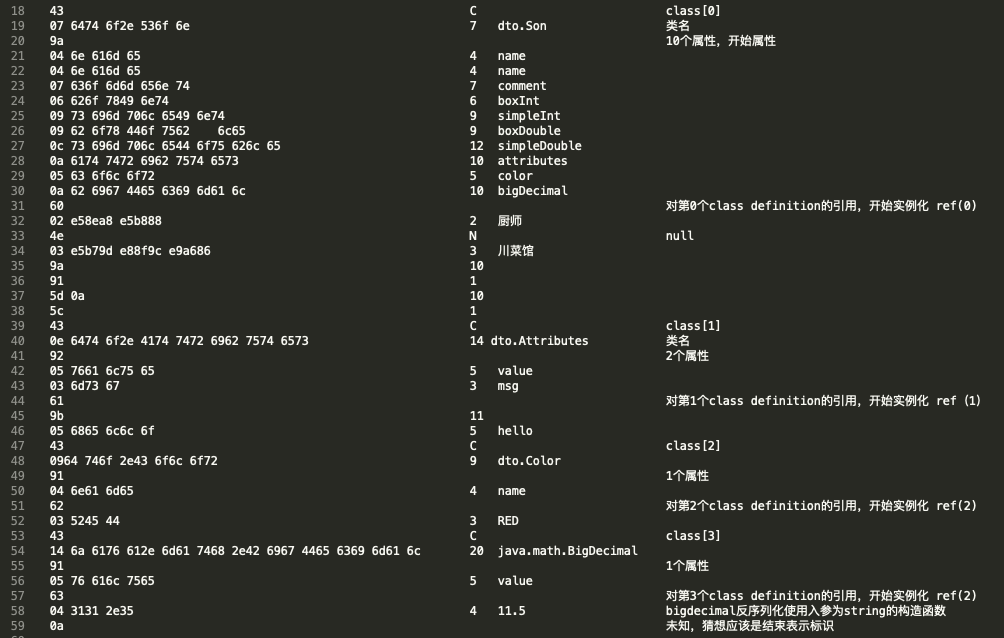
使用Hessian序列化,结果写入文件,使用vim打开。使用16进制方式查看,查看命令:%!xxd
00000000:430764746.:6:496:78446:75626:636:6002e58ea8e5b8884e03e5b79de88f9c`.:e9a6869a915d0a5c430e64746f2e4174..].\:7472696275746573920576616c756503tributes..:6d7367619b0568656c6c6f430964746fmsga..:2.:4443146:446563696d616c910576616c75656304Decimal..:31312
对其中的十六进制数逐个分析,可以拆解为一下结构:参考hessian官方文档,链接:
序列化原理
1.被序列化的类必须实现了Serializable接口
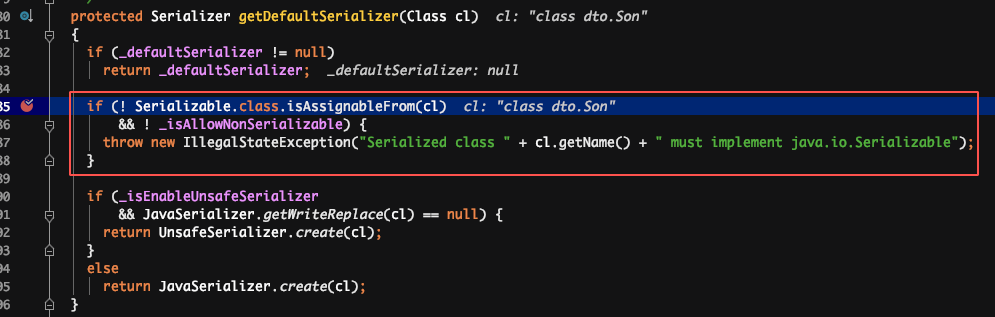
2.静态属性和transient变量,不会被序列化。
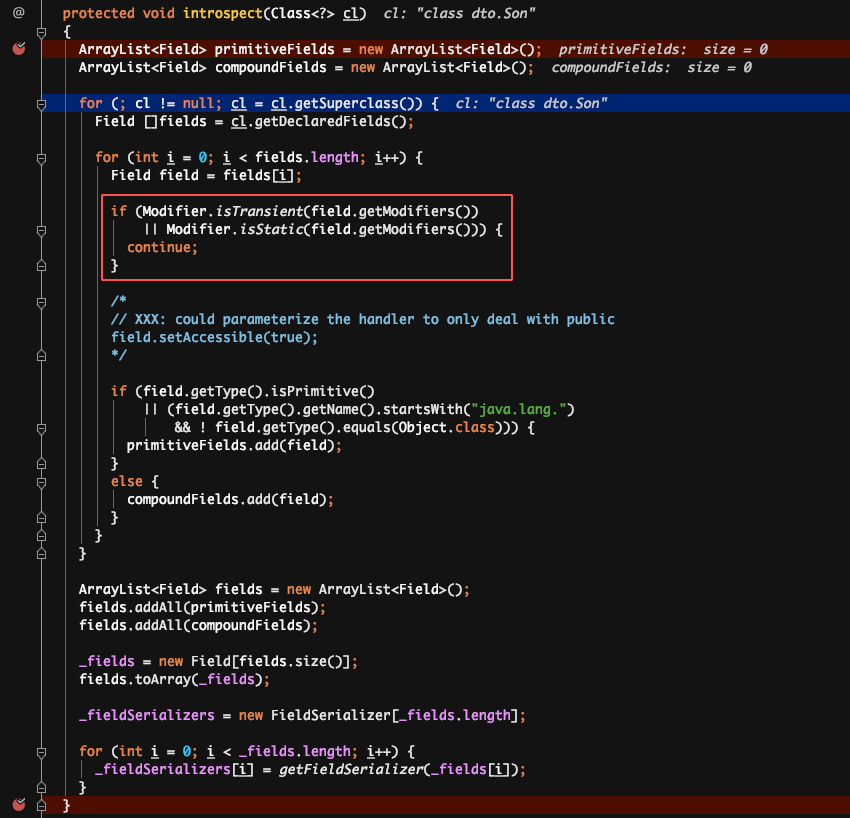
3.枚举类型在序列化后,存储的是枚举变量的名字
4.序列化结果的结构:类定义开始标识C-类名长度+类名-属性数量-(逐个)属性名长度+属性名-开始实例化标识-(按照属性名顺序,逐个设置)属性值(发现某个属性是一个对象,循环这个过程)

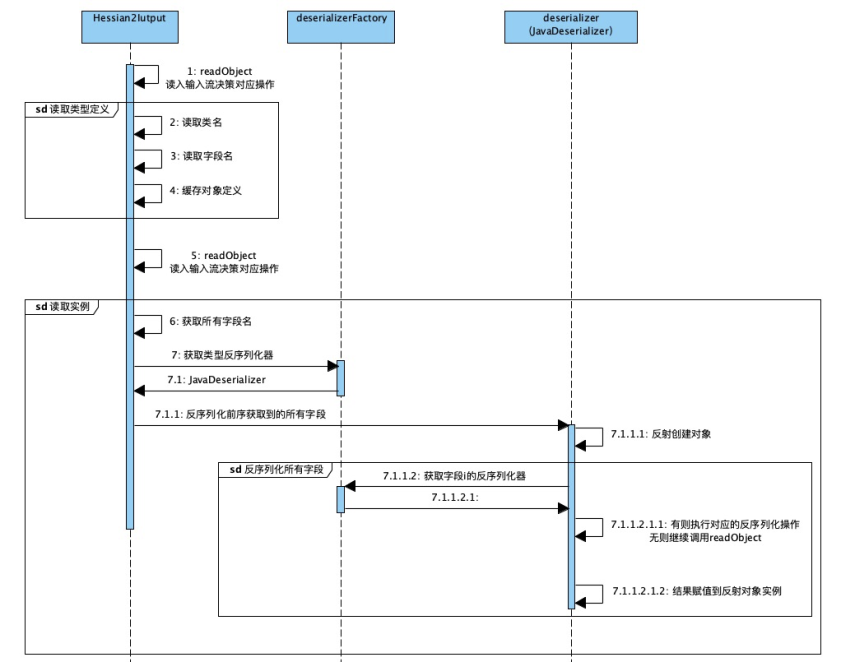
通俗原理图:
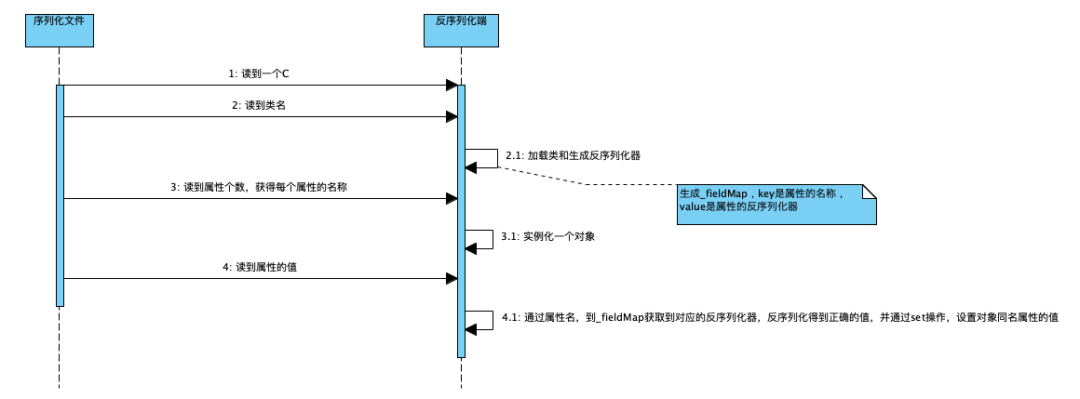
解释:这是前边的序列化文件,可以对着这个结构理解反序列化的过程。
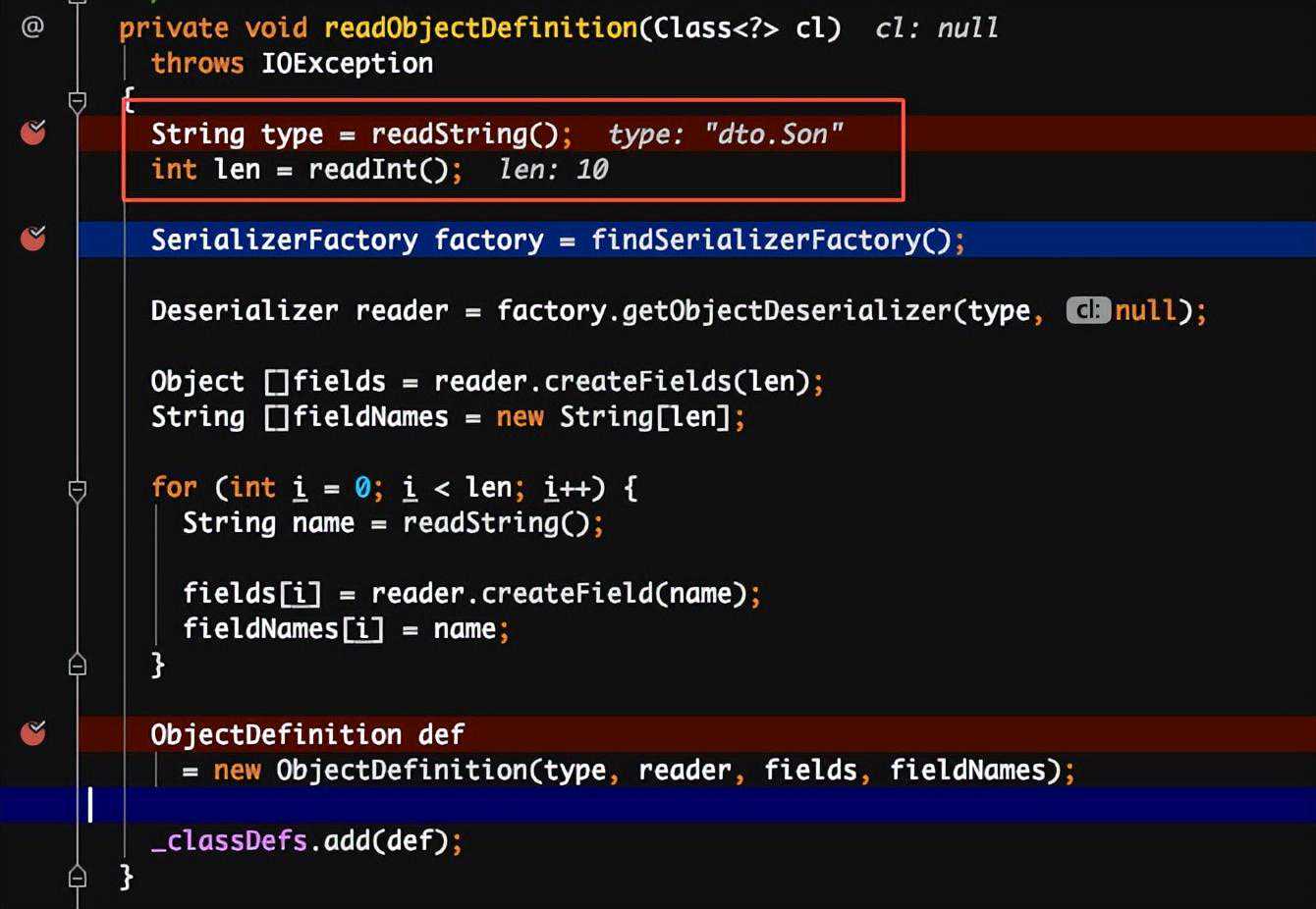
解释:读取到“C”之后,它就知道接下来是一个类的定义,接着就开始读取类名,属性个数和每个属性的名称。并把这个类的定义缓存到一个_classDefs的list里。
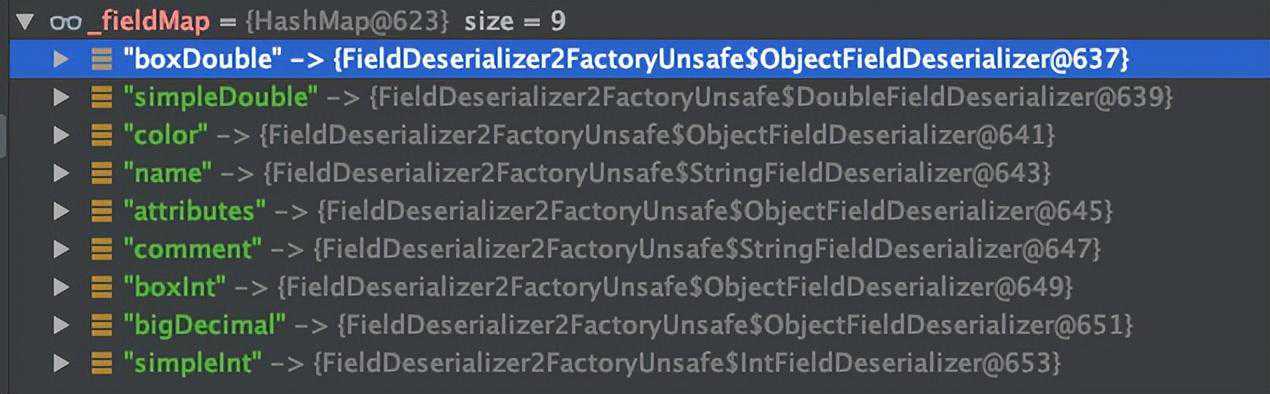
解释:通过读取序列化文件,获得类名后,会加载这个类,并生成这个类的反序列化器。这里会生成一个_fieldMap,key为反序列化端这个类所有属性的名称,value为属性对应的反序列化器。
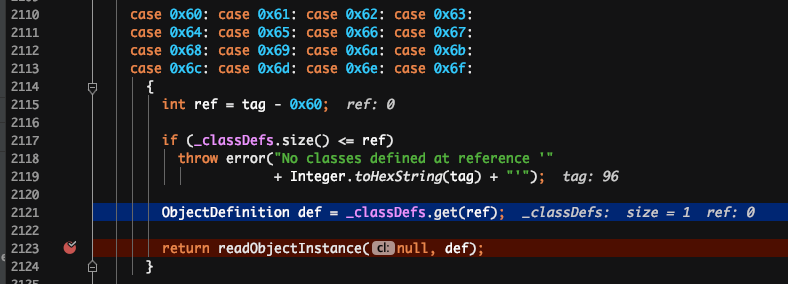
解释:读到6打头的2位十六进制数时,开始类的实例化和赋值。
遗留问题解答:增加枚举类型,反序列化不能正常读取。
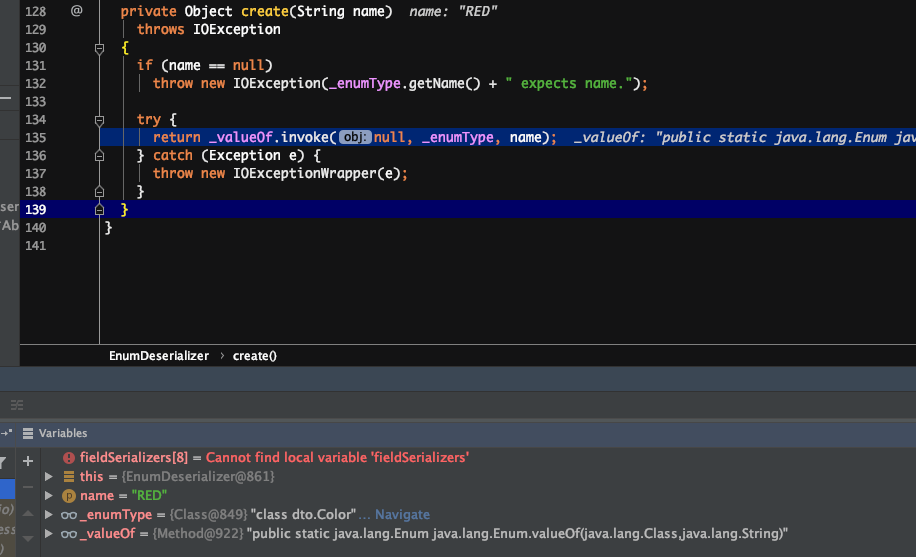
原因:枚举类型序列化结果中,枚举属性对应的值是枚举名。反序列化时,通过枚举类类名+枚举名反射生成枚举对象。枚举名找不到就会报错。
反序列化为子类型,同名属性值无法正常赋值。
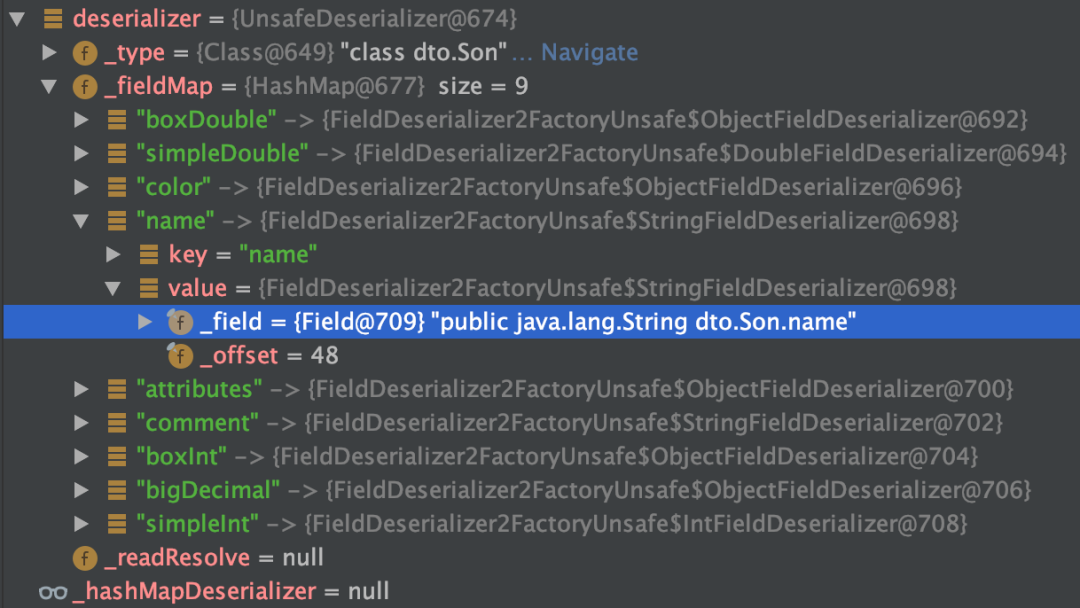


序列化对象增加参数,反序列化可以正常运行。
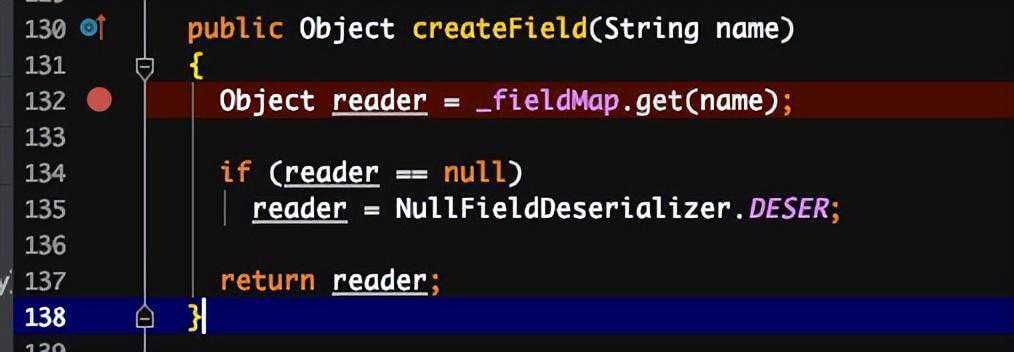
原因:反序列化时,是先通过类名加载同名类,并生成同名类的反序列化器,同名类每个属性对应的反序列化器存储在一个map中。在反序列化二进制文件时,通过读取到的属性名,到map中获取对应的反序列化器。若获取不到,默认是。待到读值的时候,仅读值,不作set操作
序列化和反序列化双方都使用对象类型时,更改属性类型,若序列化方不传输数据,序列化结果是‘N’,能正常反序列化。但是对于一方是基本类型,更改属性类型后,因为hessian对于基本类型使用不同范围的值域,所以无法正常序列化。
参考文档:hessian官方文档:序列化规则
ASCII编码对照表
:这集带你看10台60二手电拖泵。")








