虚拟机进入Guest模式后,并不会永远处于Guest模式。从Host的角度来说,VM就是Host的一个进程,一个Host上的多个VM与Host共享系统的资源。因此,当访问系统资源时,就需要退出到Host模式,由Host作为统一的管理者代为完成资源访问。
比如当虚拟机进行I/O访问时,首先需要陷入Host,VMM中的虚拟磁盘收到I/O请求后,如果虚拟机磁盘镜像存储在本地文件,那么就代为读写本地文件,如果是存储在远端集群,那么就通过网络发送到远端存储集群。再比如访问设备I/O内存映射的地址空间,当访问这些地址时,将触发页面异常,但是这些地址对应的不是内存,而是模拟设备的I/O空间,因此需要KVM介入,调用相应的模拟设备处理I/O。通常虚拟机并不会呈现Host的CPU信息,而是呈现一个指定的CPU型号,在这种情况下,显然cpuid指令也不能在Guest模式执行,需要KVM介入对cpuid指令进行模拟。
当然,除了Guest主动触发的陷入,还有一些陷入是被动触发的,比如外部时钟中断、外设的中断等。对于外部中断,一般都不是来自Guest的诉求,而只是需要Guest将CPU资源让给Host。
01访问外设前文中提到,虚拟化的3个条件之一是资源控制,即由VMM控制和协调宿主机资源给各个虚拟机,而不能由虚拟机控制宿主机的资源。以虚拟机的不同处理器之间发送核间中断为例,核间中断是由一个CPU通过其对应的LAPIC发送中断信号到目标CPU对应的LAPIC,如果不加限制地任由Guest访问CPU的物理LAPIC芯片,那么这个中断信号就可能被发送到其他物理CPU了。而对于虚拟化而言,不同的CPU只是不同的线程,核间中断本质上是在同一个进程的不同线程之间发送中断信号。当Guest的一个CPU(线程)发送核间中断时,应该陷入VMM中,由虚拟的LAPIC找到目标CPU(线程),向目标CPU(线程)注入中断。
常用的访问外设方式包括PIO(programmedI/O)和MMIO(memory-mappedI/O)。在这一节,我们重点探讨MMIO,然后简单地介绍一下PIO,更多内容将在“设备虚拟化”一章中讨论。
1.MMIO
MMIO是PCI规范的一部分,I/O设备被映射到内存地址空间而不是I/O空间。从处理器的角度来看,I/O映射到内存地址空间后,访问外设与访问内存一样,简化了程序设计。以MMIO方式访问外设时不使用专用的访问外设的指令(out、outs、in、ins),是一种隐式的I/O访问,但是因为这些映射的地址空间是留给外设的,因此CPU将产生页面异常,从而触发虚拟机退出,陷入VMM中。以LAPIC为例,其使用一个4KB大小的设备内存保存各个寄存器的值,内核将这个4KB大小的页面映射到地址空间中:
/arch/i386/kernel/_boot_cpus(void){…apic_reg=vremap(0xFEE00000,4096);…}/include/asm-i386/#defineAPIC_/include/asm-i386/__inlinevoidapic_write(unsignedlongreg,unsignedlongv){*((unsignedlong*)(apic_reg+reg))=v;}代码中地址0xFEE00000是32位x86架构为LAPIC的4KB的设备内存分配的总线地址,映射到地址空间中的逻辑地址为apic_reg。LAPIC各个寄存器都存储在这个4KB设备内存中,各个寄存器可以使用相对于4KB内存的偏移寻址。比如,icr寄存器的低32位的偏移为0x300,因此icr寄存器的逻辑地址为apic_reg+0x300,此时访问icr寄存器就像访问普通内存一样了,写icr寄存器的代码如下所示:
/arch/i386/kernel/_boot_cpus(void){…apic_write(APIC_ICR,cfg);/*Kickthesecond*/…}当Guest执行这条指令时,由于这是为LAPIC保留的地址空间,因此将触发Guest发生页面异常,进入KVM模块:
commit97222cc8316328965851ed28d23f6b64b4c912d2KVM:/drivers/kvm/_exception(structkvm_vcpu*vcpu,…){…if(is_page_fault(intr_info)){…r=kvm_mmu_page_fault(vcpu,cr2,error_code);…if(!r){…return1;}er=emulate_instruction(vcpu,kvm_run,cr2,error_code);…}…}显然对于这种页面异常,缺页异常处理函数是没法处理的,因为这个地址范围根本就不是留给内存的,所以,最后逻辑就到了函数emulate_instruction。后面我们会看到,为了提高效率和简化实现,IntelVMX增加了一种原因为apicaccess的虚拟机退出,我们会在“中断虚拟化”一章中讨论。可以毫不夸张地说,MMIO的模拟是KVM指令模拟中较为复杂的,代码非常晦涩难懂。要理解MMIO的模拟,需要对x86指令有所了解。我们首先来看一下x86指令的格式,如图1所示。

图1x86指令格式
首先是指令前缀(instructionprefixes),典型的比如lock前缀,其对应常用的原子操作。当指令前面添加了lock前缀,后面的操作将锁内存总线,排他地进行该次内存读写,高性能编程领域经常使用原子操作。此外,还有常用于mov系列指令之前的rep前缀等。
每一个指令都包含操作码(opcode),opcode就是这个指令的索引,占用1~3字节。opcode是指令编码中最重要的部分,所有的指令都必须有opcode,而其他的5个域都是可选的。
与操作码不同,操作数并不都是嵌在指令中的。操作码指定了寄存器以及嵌入在指令中的立即数,至于是在哪个寄存器、在内存的哪个位置、使用哪个寄存器索引内存位置,则由ModR/M和SIB通过编码查表的方式确定。
displacement表示偏移,immediate表示立即数。
我们以下面的代码片段为例,看一下编译器将MMIO访问翻译的汇编指令:
//*icr_reg;voidwrite(){*((unsignedlong*)icr_reg)=123;我们将上述代码片段编译为汇编指令:
核心汇编指令如下:
//_reg(%rip),%raxmovq$123,(%rax)
可见,这段MMIO访问被编译器翻译为mov指令,源操作数是立即数,目的操作数icr_reg(%rip)相当于icr寄存器映射到内存地址空间中的内存地址。因为这个地址是一段特殊的地址,所以当Guest访问这个地址,即上述第2行代码时,将产生页面异常,触发虚拟机退出,进入KVM模块。
KVM中模拟指令的入口函数是emulate_instruction,其核心部分在函数x86_emulate_memop中,结合这个函数我们来讨论一下MMIO指令的模拟:
commit97222cc8316328965851ed28d23f6b64b4c912d2KVM:/drivers/kvm/x86__emulate_memop(structx86_emulate_ctxt*ctxt,…){unsignedd;u8b,sib,twobyte=0,rex_prefix=0;…for(i=0;i8;i++){switch(b=insn_fetch(u8,1,_eip)){…d=opcode_table[b];…if(dModRM){modrm=insn_fetch(u8,1,_eip);modrm_mod|=(modrm0xc0)6;…}…switch(dSrcMask){…caseSrcImm:=OP_IMM;=(unsignedlong*)_eip;=(dByteOp)?1:op_bytes;…switch(){case1:=insn_fetch(s8,1,_eip);break;…}…switch(dDstMask){…caseDstMem:=OP_MEM;=(unsignedlong*)cr2;=(dByteOp)?1:op_bytes;…}…switch(b){…case0x880x8b:/*mov*/case0xc60xc7:/*mov(solememberofGrp11)*/=;break;…}writeback:if(!no_wb){switch(){…caseOP_MEM:…rc=ops-write_emulated((unsignedlong),,,ctxt-vcpu);…ctxt-vcpu-rip=_eip;…}函数x86_emulate_memop首先解析代码的前缀,即代码第6~8行。在处理完指令前缀后,变量b通过函数insn_fetch读入的是操作码(opcode),然后需要根据操作码判断指令操作数的寻址方式,该方式记录在一个数组opcode_table中,以操作码为索引就可以读出寻址方式,见第9行代码。如果使用了ModR/M和SIB寻址操作数,则解码ModR/M和SIB部分见第11~15行代码。
第17~29行代码解析源操作数,对于以MMIO方式写APIC的寄存器来说,源操作数是立即数,所以进入第19行代码所在的分支。因为立即数直接嵌在指令编码里,所以根据立即数占据的字节数,调用insn_fetch从指令编码中读取立即数,见第25~27行代码。为了减少代码的篇幅,这里只列出了立即数为1字节的情况。
第31~38行代码解析目的操作数,对于以MMIO方式写APIC的寄存器来说,其目的操作数是内存,所以进入第33行代码所在的分支。本质上,这条指令是因为向目的操作数指定的地址写入时引发页面异常,而引起异常的地址记录在cr2寄存器中,所以目的操作数的地址就是cr2寄存器中的地址,见第35行代码。
确定好了源操作数和目的操作数后,接下来就要模拟操作码所对应的操作了,即第40~47行代码。对于以MMIO方式写APIC的寄存器来说,其操作是mov,所以进入第42、43行代码所在分支。这里模拟了mov指令的逻辑,将源操作数的值写入目的操作数指定的地址,见第44行代码。
指令模拟完成后,需要更新指令指针,跳过已经模拟完的指令,否则会形成死循环,见第60行代码。
对于一个设备而言,仅仅简单地把源操作数赋值给目的操作数指向的地址还不够,因为写寄存器的操作可能会伴随一些副作用,需要设备做些额外的操作。比如,对于APIC而言,写icr寄存器可能需要LAPIC向另外一个处理器发出IPI中断,因此还需要调用设备的相应处理函数,这就是第56~58行代码的目的,函数指针write_emulated指向的函数为emulator_write_emulated:
commitc5ec153402b6d276fe20029da1059ba42a4b55e5KVM:enablein-kernelAPICINIT//drivers/kvm/kvm__write_emulated(unsignedlongaddr,constvoid*val,…){…returnemulator_write_emulated_onepage(addr,val,…);}staticintemulator_write_emulated_onepage(unsignedlongaddr,…){…mmio_dev=vcpu_find_mmio_dev(vcpu,gpa);if(mmio_dev){kvm_iodevice_write(mmio_dev,gpa,bytes,val);returnX86EMUL_CONTINUE;}…}函数emulator_write_emulated_onepage根据目的操作数的地址找到MMIO设备,然后kvm_iodevice_write调用具体MMIO设备的处理函数。对于LAPIC模拟设备,这个函数是apic_mmio_write。如果Guest内核写的是icr寄存器,可以清楚地看到伴随着这个“写icr寄存器”的动作,LAPIC还有另一个副作用,即向其他CPU发送IPI:
commitc5ec153402b6d276fe20029da1059ba42a4b55e5KVM:enablein-kernelAPICINIT//drivers/kvm/_mmio_write(structkvm_io_device*this,…){…caseAPIC_ICR:…apic_s_ipi(apic);…}鉴于LAPIC的寄存器的访问非常频繁,所以Intel从硬件层面做了很多支持,比如为访问LAPIC的寄存器增加了专门退出的原因,这样就不必首先进入缺页异常函数来尝试处理,当缺页异常函数无法处理后再进入指令模拟函数,而是直接进入LAPIC的处理函数:
commitf78e0e2ee498e8f847500b565792c7d7634dcf54KVM:VMX:EnablememorymappedTPRshadow(FlexPriority)/drivers/kvm/(*kvm_vmx_exit_handlers[])(…)={…[EXIT_REASON_APIC_ACCESS]=handle_apic_access,};staticinthandle_apic_access(structkvm_vcpu*vcpu,…){…er=emulate_instruction(vcpu,kvm_run,0,0,0);…}2.PIO
PIO使用专用的I/O指令(out、outs、in、ins)访问外设,当Guest通过这些专门的I/O
指令访问外设时,处于Guest模式的CPU将主动发生陷入,进入VMM。IntelPIO指令支持两种模式,一种是普通的I/O,另一种是stringI/O。普通的I/O指令一次传递1个值,对应于x86架构的指令out、in?;stringI/O指令一次传递多个值,对应于x86架构的指令outs、ins。因此,对于普通的I/O,只需要记录下val,而对于stringI/O,则需要记录下I/O值所在的地址。
我们以向块设备写数据为例,对于普通的I/O,其使用的是out指令,格式如表1所示。
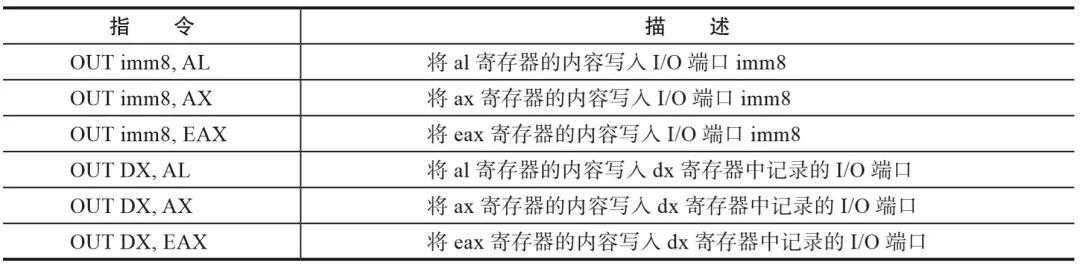
表1out指令格式
我们可以看到,无论哪种格式,out指令的源操作数都是寄存器al、ax、eax系列。因此,当陷入KVM模块时,KVM模块可以从Guest的rax寄存器的值中取出Guest准备写给外设的值,KVM将这个值存储到结构体kvm_run中。对于string类型的I/O,需要记录的是数据所在的内存地址,这个地址在陷入KVM前,CPU会将其记录在VMCS的字段GUEST_LINEAR_ADDRESS中,KVM将这个值从VMCS中读出来,存储到结构体kvm_run中:
commit6aa8b732ca01c3d7a54e93f4d701b8aabbe60fb7[PATCH]kvm:/drivers/kvm/_io(structkvm_vcpu*vcpu,…){…if(kvm_){…kvm_=vmcs_readl(GUEST_LINEAR_ADDRESS);}elsekvm_=vcpu-regs[VCPU_REGS_RAX];/*rax*/return0;}然后,程序的执行流程流转到I/O模拟设备,模拟设备将从结构体kvm_run中取出I/O相关的值,存储到本地文件镜像或通过网络发给存储集群。I/O模拟的更多细节我们将在“设备虚拟化”一章讨论。
02特殊指令有一些指令从机制上可以直接在Guest模式下本地运行,但是其在虚拟化上下文的语义与非虚拟化下完全不同。比如cpuid指令,在虚拟化上下文运行这条指令时,其本质上并不是获取物理CPU的特性,而是获取VCPU的特性;再比如hlt指令,在虚拟化上下文运行这条指令时,其本质上并不是停止物理CPU的运行,而是停止VCPU的运行。所以,这种指令需要陷入KVM进行模拟,而不能在Guest模式下本地运行。在这一节,我们以这两个指令为例,讨论这两个指令的模拟。
1.cpuid指令模拟
cpuid指令会返回CPU的特性信息,如果直接在Guest模式下运行,获取的将是宿主机物理CPU的各种特性,但是实际上,通过一个线程模拟的CPU的特性与物理CPU可能会有很大差别。比如,因为KVM在指令、设备层面通过软件方式进行了模拟,所以这个模拟的CPU可能要比物理CPU支持更多的特性。再比如,对于虚拟机而言,其可能在不同宿主机、不同集群之间迁移,因此也需要从虚拟化层面给出一个一致的CPU特性,所以cpuid指令需要陷入VMM特殊处理。
Intel手册中对cpuid指令的描述如表2所示。

表2cpuid指令
cpuid指令使用eax寄存器作为输入参数,有些情况也需要使用ecx寄存器作为输入参数。比如,当eax为0时,在执行完cpuid指令后,eax中包含的是支持最大的功能(function)号,ebx、ecx、edx中是CPU制造商的ID;当eax值为2时,执行cpuid指令后,将在寄存器eax、ebx、ecx、edx中返回包括TLB、Cache、Prefetch的信息;再比如,当eax值为7,ecx值为0时,将在寄存器eax、ebx、ecx、edx中返回处理器扩展特性。
起初,KVM的用户空间通过cpuid指令获取Host的CPU特征,加上用户空间的配置,定义好VCPU支持的CPU特性,传递给KVM内核模块。KVM模块在内核中定义了接收来自用户空间定义的CPU特性的结构体:
commit06465c5a3aa9948a7b00af49cd22ed8f235cdb0fKVM:/include/linux/_cpuid_entry{__u32function;__u32eax;__u32ebx;__u32ecx;__u32edx;__u32padding;};用户空间按照如下结构体kvm_cpuid的格式组织好CPU特性后,通过如下KVM模块提供的接口传递给KVM内核模块:
commit06465c5a3aa9948a7b00af49cd22ed8f235cdb0fKVM:/include/linux//*forKVM_SET_CPUID*/structkvm_cpuid{__u32nent;__u32padding;structkvm_cpuid_entryentries[0];};/drivers/kvm/kvm__vcpu_ioctl(structfile*filp,unsignedintioctl,unsignedlongarg){…caseKVM_SET_CPUID:{structkvm_cpuid__user*cpuid_arg=argp;structkvm_cpuidcpuid;…if(copy_from_user(cpuid,cpuid_arg,sizeofcpuid))gotoout;r=kvm_vcpu_ioctl_set_cpuid(vcpu,cpuid,cpuid_arg-entries);…}staticintkvm_vcpu_ioctl_set_cpuid(structkvm_vcpu*vcpu,structkvm_cpuid*cpuid,structkvm_cpuid_entry__user*entries){…if(copy_from_user(vcpu-cpuid_entries,entries,cpuid-nent*sizeof(structkvm_cpuid_entry)))…}KVM内核模块将用户空间组织的结构体kvm_cpuid复制到内核的结构体kvm_cpuid_entry实例中。首次读取时并不确定entry的数量,所以第1次读取结构体kvm_cpuid,其中的字段nent包含了entry的数量,类似读消息头。获取了entry的数量后,再读结构体中包含的entry。所以从用户空间到内核空间的复制执行了两次。
事实上,除了硬件支持的CPU特性外,KVM内核模块还提供了一些软件方式模拟的特性,所以用户空间仅从硬件CPU读取特性是不够的。为此,KVM后来实现了2.0版本的cpuid指令的模拟,即cpuid2,在这个版本中,KVM内核模块为用户空间提供了接口,用户空间可以通过这个接口获取KVM可以支持的CPU特性,其中包括硬件CPU本身支持的特性,也包括KVM内核模块通过软件方式模拟的特性,用户空间基于这个信息构造VCPU的特征。具体内容我们就不展开介绍了。
在Guest执行cpuid指令发生VMexit时,KVM会根据eax中的功能号以及ecx中的子功能号,从kvm_cpuid_entry实例中索引到相应的entry,使用entry中的eax、ebx、ecx、edx覆盖结构体vcpu中的数组regs中相应的字段。当再次切入Guest时,KVM会将它们加载到物理CPU的通用寄存器,这样在进入Guest后,Guest就可以从这几个寄存器读取CPU相关信息和特性。相关代码如下:
commit06465c5a3aa9948a7b00af49cd22ed8f235cdb0fKVM:Handlecpuidinthekernelinsteadofpuntingtouserspacevoidkvm_emulate_cpuid(structkvm_vcpu*vcpu){inti;u32function;structkvm_cpuid_entry*e,*best;…function=vcpu-regs[VCPU_REGS_RAX];…for(i=0;ivcpu-cpuid_nent;++i){e=vcpu-cpuid_entries[i];if(e-function==function){best=e;break;}…}if(best){vcpu-regs[VCPU_REGS_RAX]=best-eax;vcpu-regs[VCPU_REGS_RBX]=best-ebx;vcpu-regs[VCPU_REGS_RCX]=best-ecx;vcpu-regs[VCPU_REGS_RDX]=best-edx;}…kvm_arch_ops-skip_emulated_instruction(vcpu);}最后,我们以一段用户空间处理cpuid的过程为例结束本节。假设我们虚拟机所在的集群由小部分支持AVX2的和大部分不支持AVX2的机器混合组成,为了可以在不同类型的Host之间迁移虚拟机,我们计划CPU的特征不支持AVX2指令。我们首先从KVM内核模块获取其可以支持的CPU特征,然后清除AVX2指令的支持,代码大致如下:
structkvm_cpuid2*kvm_cpuid;kvm_cpuid=(structkvm_cpuid2*)malloc(sizeof(*kvm_cpuid)+CPUID_ENTRIES*sizeof(*kvm_cpuid-entries));kvm_cpuid-nent=CPUID_ENTRIES;ioctl(vcpu_fd,KVM_GET_SUPPORTED_CPUID,kvm_cpuid);for(i=0;ikvm_cpuid-nent;i++){structkvm_cpuid_entry2*entry=kvm_cpuid-entries[i];if(entry-function==7){/*ClearAVX2*/entry-ebx=~(16);break;};}ioctl(vcpu_fd,KVM_SET_CPUID2,kvm_cpuid);2.hlt指令模拟
当处理器执行hlt指令后,将处于停机状态(Halt)。对于开启了超线程的处理器,hlt指令是停止的逻辑核。之后如果收到NMI、SMI中断,或者reset信号等,则恢复运行。但是,对于虚拟机而言,如果任凭Guest的某个核本地执行hlt,将导致物理CPU停止运行,然而我们需要停止的只是Host中用于模拟CPU的线程。因此,Guest执行hlt指令时需要陷入KVM中,由KVM挂起VCPU对应的线程,而不是停止物理CPU:
commitb6958ce44a11a9e9425d2b67a653b1ca2a27796fKVM:/drivers/kvm/_halt(structkvm_vcpu*vcpu,…){skip_emulated_instruction(vcpu);returnkvm_emulate_halt(vcpu);}/drivers/kvm/kvm__emulate_halt(structkvm_vcpu*vcpu){…kvm_vcpu_kernel_halt(vcpu);…}staticvoidkvm_vcpu_kernel_halt(structkvm_vcpu*vcpu){…while(!(irqchip_in_kernel(vcpu-kvm)kvm_cpu_has_interrupt(vcpu))!vcpu-irq_summary!signal_ping(current)){set_current_state(TASK_INTERRUPTIBLE);…schedule();…}…set_current_state(TASK_RUNNING);}VCPU对应的线程将自己设置为可被中断的状态(TASK_INTERRUPTIBLE),然后主动调用内核的调度函数schedule()将自己挂起,让物理处理器运行其他就绪任务。当挂起的VCPU线程被其他任务唤醒后,将从schedule()后面的一条语句继续运行。当准备进入下一次循环时,因为有中断需要处理,则跳出循环,将自己设置为就绪状态,接下来VCPU线程则再次进入Guest模式。
03访问具有副作用的寄存器Guest在访问CPU的很多寄存器时,除了读写寄存器的内容外,一些访问会产生副作用。对于这些具有副作用的访问,CPU也需要从Guest陷入VMM,由VMM进行模拟,也就是完成副作用。
典型的比如前面提到的核间中断,对于LAPIC而言,写中断控制寄存器可能需要LAPIC向另外一个处理器发送核间中断,发送核间中断就是写中断控制寄存器这个操作的副作用。因此,当Guest访问LAPIC的中断控制寄存器时,CPU需要陷入KVM中,由KVM调用虚拟LAPIC芯片提供的函数向目标CPU发送核间中断。
再比如地址翻译,每当Guest内切换进程,Guest的内核将设置cr3寄存器指向即将运行的进程的页表。而当使用影子页表机制完成虚拟机地址(GVA)到宿主机物理地址(HPA)的映射时,我们期望物理CPU的cr3寄存器指向KVM为Guest中即将投入运行的进程准备的影子页表,因此当Guest切换进程时,CPU需要从Guest陷入KVM中,让KVM将cr3寄存器设置为指向影子页表。因此,当使用影子页表机制时,KVM需要设置VMCS中的Processor-BasedVM-ExecutionControls的第15位CR3-loadexiting,当设置了CR3-loadexiting后,每当Guest访问物理CPU的cr3寄存器时,都将触发物理CPU陷入KVM,KVM调用函数handle_cr设置cr3寄存器指向影子页表,如下代码所示。
commit6aa8b732ca01c3d7a54e93f4d701b8aabbe60fb7[PATCH]kvm:/drivers/kvm/_cr(structkvm_vcpu*vcpu,…){u64exit_qualification;intcr;intreg;exit_qualification=vmcs_read64(EXIT_QUALIFICATION);cr=exit_qualification15;reg=(exit_qualification8)15;switch((exit_qualification4)3){case0:/*movtocr*/switch(cr){…case3:vcpu_load_rsp_rip(vcpu);set_cr3(vcpu,vcpu-regs[reg]);skip_emulated_instruction(vcpu);return1;…}*本文经出版社授权发布,更多关于虚拟化技术的内容推荐阅读《深度探索Linux系统虚拟化:原理与实现》。










