提到处理器结构,有2个指标是经常要考虑的:延迟和吞吐量。所谓延迟,是指从发出指令到最终返回结果中间经历的时间间隔。而所谓吞吐量,就是单位之间内处理的指令的条数。
下图1是CPU的示意图。从图中可以看出CPU的几个特点:
CPU中包含了多级高速的缓存结构。因为我们知道处理运算的速度远高于访问存储的速度,那么奔着空间换时间的思想,设计了多级高速的缓存结构,将经常访问的内容放到低级缓存中,将不经常访问的内容放到高级缓存中,从而提升了指令访问存储的速度。
CPU中包含了很多控制单元。具体有2种,一个是分支预测机制,另一个是流水线前传机制。
CPU的运算单元(Core)强大,整型浮点型复杂运算速度快。
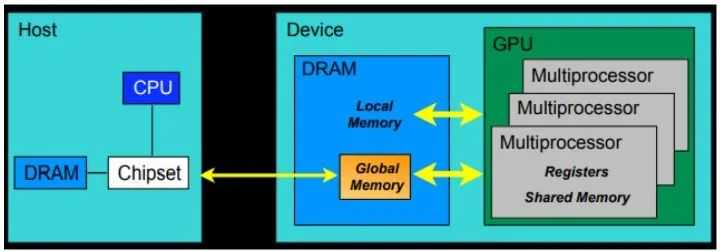
图1:CPU的示意图
所以综合以上三点,CPU在设计时的导向就是减少指令的时延,我们称之为延迟导向设计,如下图3所示。
下图2是GPU的示意图,它与之前CPU的示意图相比有着非常大的不同。从图中可以看出GPU的几个特点(注意紫色和黄色的区域分别是缓存单元和控制单元):
GPU中虽有缓存结构但是数量少。因为要减少指令访问缓存的次数。
GPU中控制单元非常简单。控制单元中也没有分支预测机制和数据转发机制。对于复杂的指令运算就会比较慢。
GPU的运算单元(Core)非常多,采用长延时流水线以实现高吞吐量。每一行的运算单元的控制器只有一个,意味着每一行的运算单元使用的指令是相同的,不同的是它们的数据内容。那么这种整齐划一的运算方式使得GPU对于那些控制简单但运算高效的指令的效率显著增加。
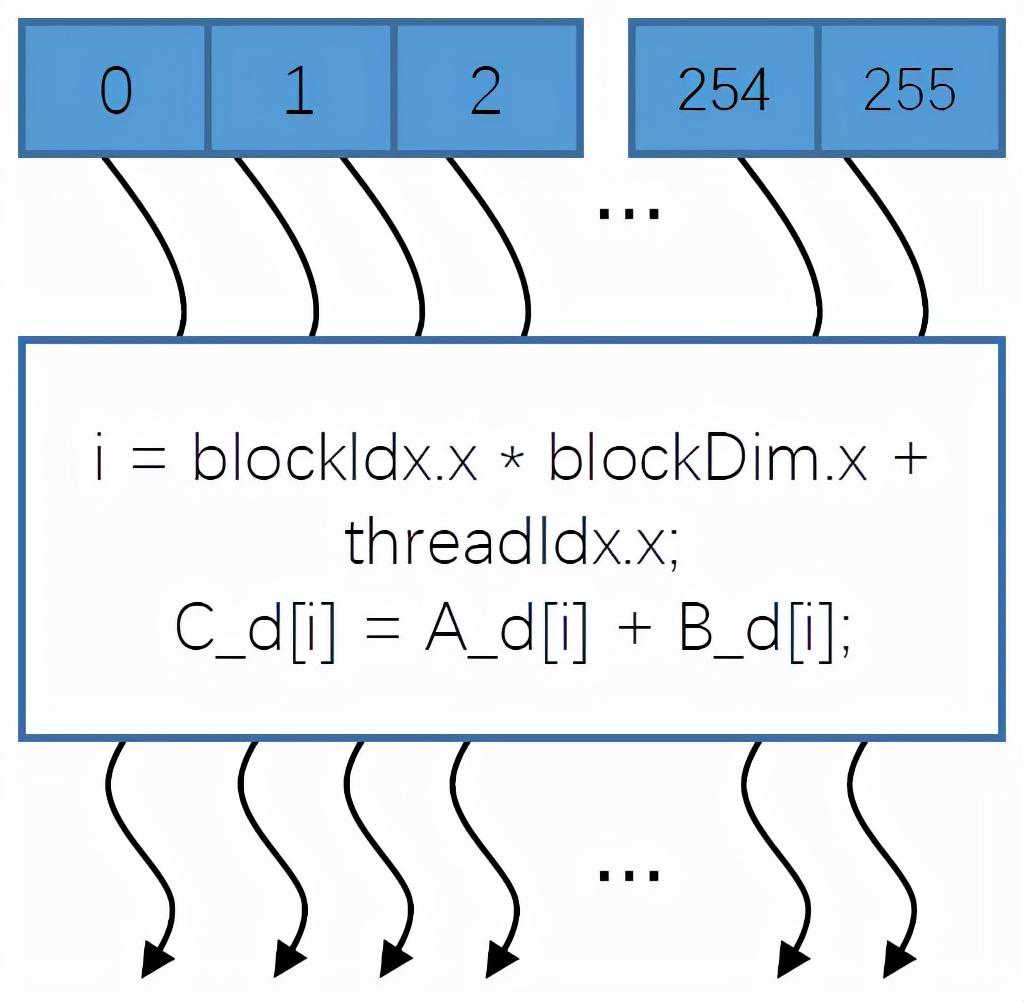
图2:GPU的示意图
所以,GPU在设计过程中以一个原则为核心:增加简单指令的吞吐。因此,我们称GPU为吞吐导向设计,,如下图3所示。

图3:CPU是延迟导向设计,GPU是吞吐导向设计
那么究竟在什么情况下使用CPU,什么情况下使用GPU呢?
CPU在连续计算部分,延迟优先,CPU比GPU,单条复杂指令延迟快10倍以上。
GPU在并行计算部分,吞吐优先,GPU比CPU,单位时间内执行指令数量10倍以上。
适合GPU的问题:
计算密集:数值计算的比例要远大于内存操作,因此内存访问的延时可以被计算掩盖。
数据并行:大任务可以拆解为执行相同指令的小任务,因此对复杂流程控制的需求较低。
2CUDA编程的重要概念CUDA(ComputeUnifiedDeviceArchitecture),由英伟达公司2007年开始推出,初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语。
OpenCL(OpenComputingLanguge)是2008年发布的异构平台并行编程的开放标准,也是一个编程框架。OpenCL相比CUDA,支持的平台更多,除了GPU还支持CPU、DSP、FPGA等设备。
下面我们将以CUDA为例,介绍GPU编程的基本思想和基本操作。
首先主机端(host)和设备端(device),主机端一般指我们的CPU,设备端一般指我们的GPU。
一个CUDA程序,我们可以把它分成3个部分:
第1部分是:从主机(host)端申请devicememory,把要拷贝的内容从hostmemory拷贝到申请的devicememory里面。
第2部分是:设备端的核函数对拷贝进来的东西进行计算,来得到和实现运算的结果,图4中的Kernel就是指在GPU上运行的函数。
第3部分是:把结果从devicememory拷贝到申请的hostmemory里面,并且释放设备端的显存和内存。
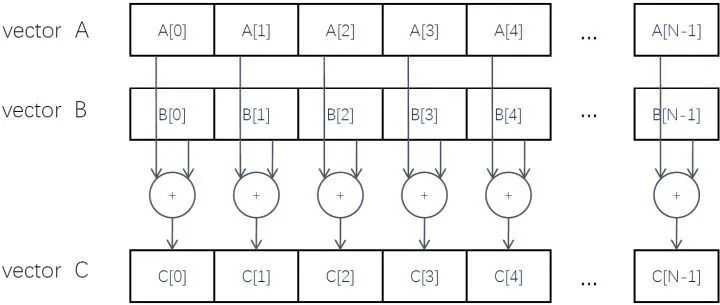
图4:一个CUDA程序可以分成3个部分
CUDA编程中的内存模型
这里就引出了一个非常重要的概念就是CUDA编程中的内存模型。
从硬件的角度来讲:
CUDA内存模型的最基本的单位就是SP(线程处理器)。每个线程处理器(SP)都用自己的registers(寄存器)和localmemory(局部内存)。寄存器和局部内存只能被自己访问,不同的线程处理器之间呢是彼此独立的。
由多个线程处理器(SP)和一块共享内存所构成的就是SM(多核处理器)(灰色部分)。多核处理器里边的多个线程处理器是互相并行的,是不互相影响的。每个多核处理器(SM)内都有自己的sharedmemory(共享内存),sharedmemory可以被线程块内所有线程访问。
再往上,由这个SM(多核处理器)和一块全局内存,就构成了GPU。一个GPU的所有SM共有一块globalmemory(全局内存),不同线程块的线程都可使用。
上面这段话可以表述为:每个thread都有自己的一份register和localmemory的空间。同一个block中的每个thread则有共享的一份sharememory。此外,所有的thread(包括不同block的thread)都共享一份globalmemory。不同的grid则有各自的globalmemory。

图5:CUDA内存模型,硬件角度
从软件的角度来讲:
线程处理器(SP)对应线程(thread)。
多核处理器(SM)对应线程块(threadblock)。
设备端(device)对应线程块组合体(grid)。

图6:CUDA内存模型,软件角度
如下图6所示,所谓线程块内存模型在软件侧的一个最基本的执行单位,所以我们从这里开始梳理。线程块就是线程的组合体,它具有如下这些特点:
块内的线程通过共享内存、原子操作和屏障同步进行协作(sharedmemory,atomicoperationsandbarriersynchronization)
不同块中的线程不能协作。
如下图7所示的线程块就是由256个线程组成的,它执行的任务就是一个最基本的向量相加的一个操作。在线程块内,这256个线程的计算是彼此互相独立的,并行的。下面的这个[i],就是如何确定每个线程的索引(在显存中的位置)。在计算完以后(图中弯箭头的头部),会设置一个时钟,将这256个线程的计算结果进行同步。

图7:一个256个线程组成的线程块
以上就是一个256位向量的加的操作的并行处理方法,得到最终的向量加的结果。
所谓网格(grid),其实就是线程块的组合体,如下图8所示。
网格(grid)内的线程块是彼此互相独立,互不影响的。
全局内存可以由所有的线程块进行访问。
CUDA核函数由线程网格(数组)执行。每个线程都有一个索引,用于计算内存地址和做出控制决策。在计算完以后(图中所有弯箭头的头部),会设置一个时钟,将这N个线程块的计算结果进行同步。
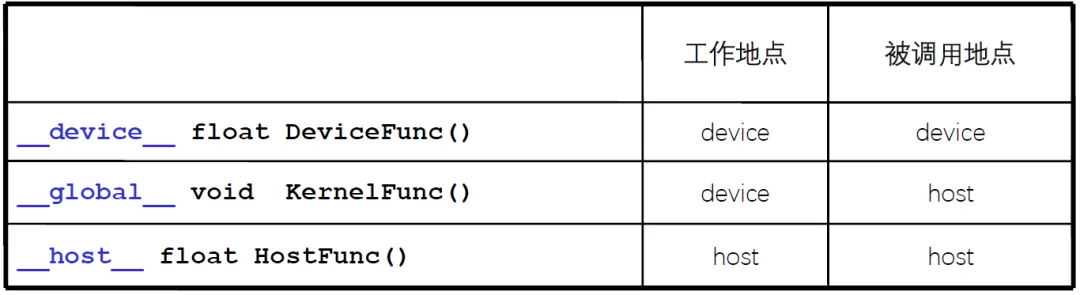
图8:网格就是线程块的组合体
线程块id线程id:定位独立线程的门牌号
核函数需要确定每个线程在显存中的位置,我们之前提到CUDA的核函数是要在设备端来进行计算和处理的,在执行核函数时需要访问到每个线程的registers(寄存器)和localmemory(局部内存)。在这个过程中需要确定每一个线程在显存上的位置。所以我们需要像图9那样使用线程块的index和线程的index来确定线程在显存上的位置。
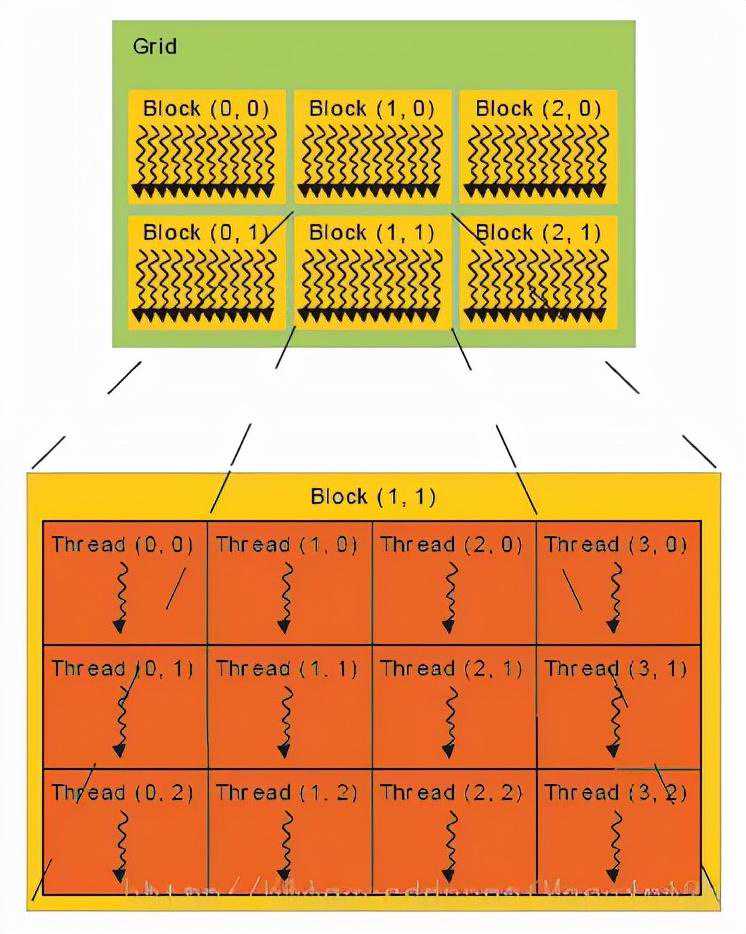
图9:使用线程块的index和线程的index来确定线程在显存上的位置
如图9所示,图9中的线程块索引是2维的,每个网格都由2×2个线程块组成;线程索引是3维的,每个线程块都由2×4×2个线程组成,所以代码应该是:
图10:线程Id计算
图10中:M=N=2,P,Q,S=2,4,2。
每个线程x的那一维应该是线程块的索引×线程块的x维度大小+线程的索引。(设备端线程x的那一维的索引)。
每个线程y的那一维应该是线程块的索引×线程块的y维度大小+线程的索引。(设备端线程y的那一维的索引)。
线程束(warp)
前面我们提到,如图11所示的每一行由1个控制单元加上若干计算单元所组成,这些所有的计算单元执行的控制指令是一个。这其实就是个非常典型的"单指令多数据流机制"。
图11:一个线程束(warp):采用单指令多数据流机制
单指令多数据流机制是说:执行的指令是一条,只不过不同的计算单元使用的数据是不一样的。而上面这一行,我们就称之为一个线程束(warp)。
所以,SM采用的SIMT(Single-Instruction,Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元。一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。一个warp只包含一条指令,所以:warp本质上是线程在GPU上运行的最小单元。
由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数。
当一个kernel被执行时,grid中的线程块被分配到SM(多核处理器)上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的SingleInstructionMultipleThread(SIMT),如图12所示。
图12:SingleInstructionMultipleThread(SIMT)
3并行计算向量相加下面我们就用一个实际的例子来看看CUDA编程具体是如何操作的。例子就是两个长度为N的张量相加,如下图13所示。
图13:两个张量相加
在CPU中完成相加的操作很简单:
//ComputevectorsumC=A+BvoidvecAdd(float*A,float*B,float*C,intn){for(i=0,in,i++)C[i]=A[i]+B[i];}intmain(){//MemoryallocationforA_h,B_h,andC_h//I/OtoreadA_handB_h,Nelements…vecAdd(A_h,B_h,C_h,N);}要在GPU中完成这一操作,首先我们想一下它是否适合使用GPU,我们当时总结了四个特点:
访问内存次数少,满足。
控制指令简单,无复杂分枝预测,跳转指令,满足。
计算指令简单,满足,是简单的加法操作。
并行度高,满足,不同的[i]之间不互相影响。
所以,向量相家的任务适合在GPU上编程。
再回顾下GPU运算步骤,如图4所示:
一个CUDA程序,我们可以把它分成3个部分:
第1部分是:从主机(host)端申请devicememory,把要拷贝的内容从hostmemory拷贝到申请的devicememory里面。
第2部分是:设备端的核函数对拷贝进来的东西进行计算,来得到和实现运算的结果,图4中的Kernel就是指在GPU上运行的函数。
第3部分是:把结果从devicememory拷贝到申请的hostmemory里面,并且释放设备端的显存和内存。
如下:
下面就是具体的C++代码实现:
voidvecAdd(float*A,float*B,float*C,intn){intsize=n*sizeof(float);float*A_d,*B_d,*C_d;1.//TransferAandBtodevicememorycudaMalloc((void**)A_d,size);cudaMemcpy(A_d,A,size,cudaMemcpyHostToDevice);cudaMalloc((void**)B_d,size);cudaMemcpy(B_d,B,size,cudaMemcpyHostToDevice);//AllocatedevicememoryforcudaMalloc((void**)C_d,size);2.//Kernelinvocationcode–tobeshownlater…3.//TransferCfromdevicetohostcudaMemcpy(C,C_d,size,cudaMemcpyDeviceToHost);//FreedevicememoryforA,B,CcudaFree(A_d);cudaFree(B_d);cudaFree(C_d);}下面我们进入最重要的部分,即:如何自己书写一个kernel函数。
核函数调用的注意事项
在GPU上执行的函数。
一般通过标识符__global__修饰。
调用通过参数1,参数2,用于说明内核函数中的线程数量,以及线程是如何组织的。
以网格(Grid)的形式组织,每个线程格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。
调用时必须声明内核函数的执行参数。
在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误。
CUDA编程的标识符号
不同的表示符号对应着不同的工作地点和被调用地点。核函数使用__global__标识,必须返回void。__device____host__可以一起用。
图17:CUDA编程的标识符号
下面,按照我们刚才的对核函数的介绍,我们展示了向量相加的代码。
代码讲解:
首先,看到__global__标识,返回的是void,就意味着vecAddKernel函数是一个在host端调用,在device端执行的核函数。它的三个参数就是我们之前申请好的指向三段显存的指针。
通过inti=+*;(线程的索引,线程块的索引,线程块维度的大小)来计算好要访问的线程的索引的位置。
那么如何在主机端调用呢?我们使用尖括号**网格grid维度,线程块block维度**来包括:线程块数ceil(n/256)和一个线程块的线程数256。
图18:向量相加的代码
第1步主机端__host__修饰:申请显存,内存。显存,内存的互相拷贝。内存,显存释放。比如图19中申请的网格是ceil(n/256)维的代表一个网格有ceil(n/256)个线程块;线程块是256维的,代表一个线程块有256个线程。
第2步设备端__global__修饰:计算索引绝对位置,并行计算。
图19:主机端和设备端代码
详细地讲,核函数只能在主机端调用,调用时必须申明执行参数。调用形式如下:
KernelDg,Db,Ns,S(paramlist);
运算符内是核函数的执行参数,告诉编译器运行时如何启动核函数,用于说明内核函数中的线程数量,以及线程是如何组织的。
运算符对kernel函数完整的执行配置参数形式是Dg,Db,Ns,S
参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3Dg(,,1)表示grid中每行有个block,每列有个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有*个block,其中和最大值为65535。
参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3Db(,,)表示整个block中每行有个thread,每列有个thread,高度为。和最大值为512,最大值为62。一个block中共有**个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
参数Ns是一个可选参数,用于设置每个block除了静态分配的sharedMemory以外,最多能动态分配的sharedmemory大小,单位为byte。不需要动态分配时该值为0或省略不写。
参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
最后我们简单介绍下CUDA编程如何执行编译的过程。因为我们之前在CPU上编程,使用g++或gcc进行编译,再通过link生成可执行程序。那么在GPU端,编译器就是NVCC(NVIDIACudacompilerdriver)。
通常我们会把和GPU相关的头文件放在.h文件里,把设备端执行的程序(__global__定义的函数)放在.cu文件里,这些程序我们用NVCC来进行编译。主机端的程序放在.h和.cpp里面,这些程序我们可以继续用g++或gcc来进行编译。
通常我们有这几种编译的方法:
逐个文件编译(GPU和CPU的程序都编译成.o文件。最后把它们汇总在一起,并link为一个可执行文件.exe),但是这只适用于文件数较少的情况,当文件数较多时,这种办法就显得比较复杂。
使用cmake方式编译,写一个,下文有介绍。
图20:CUDA编程如何执行编译的过程
CUDA中threadIdx,blockIdx,blockDim,gridDim的使用
threadIdx是一个uint3类型,表示一个线程的索引。
blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim是一个dim3类型,表示线程块的大小。
gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
下面这张图21比较清晰的表示的几个概念的关系:
图21:几个变量的关系
cuda通过符号来分配索引线程的方式,我知道的一共有15种索引方式。
4实践4.1向量相加CUDA代码这一节我们通过一个实例直观感受下CUDA并经计算究竟能使这些计算简单,并行度高的操作加速多少。
我们先看一下CPU执行向量相加的代码:
includecstdlibincludeiostreamincludesys/#includecuda_;__global__voidvecAddKernel(float*A_d,float*B_d,float*C_d,intn){inti=+*;if(in)C_d[i]=A_d[i]+B_d[i];}intmain(intargc,char*argv[]){intn=atoi(argv[1]);coutnl;size_tsize=n*sizeof(float);//hostmemeryfloat*a=(float*)malloc(size);float*b=(float*)malloc(size);float*c=(float*)malloc(size);for(inti=0;in;i++){floataf=rand()/double(RAND_MAX);floatbf=rand()/double(RAND_MAX);a[i]=af;b[i]=bf;}float*da=NULL;float*db=NULL;float*dc=NULL;cudaMalloc((void**)da,size);cudaMalloc((void**)db,size);cudaMalloc((void**)dc,size);cudaMemcpy(da,a,size,cudaMemcpyHostToDevice);cudaMemcpy(db,b,size,cudaMemcpyHostToDevice);cudaMemcpy(dc,c,size,cudaMemcpyHostToDevice);structtimevalt1,t2;intthreadPerBlock=256;intblockPerGrid=(n+threadPerBlock-1)/threadPerBlock;printf("threadPerBlock:%d\nblockPerGrid:%d\n",threadPerBlock,blockPerGrid);gettimeofday(t1,NULL);vecAddKernelblockPerGrid,threadPerBlock(da,db,dc,n);gettimeofday(t2,NULL);cudaMemcpy(c,dc,size,cudaMemcpyDeviceToHost);//for(inti=0;i10;i++)//coutvecA[i]""vecB[i]""vecC[i]l;doubletimeuse=(__sec)+(double)(__usec)/1000000.0;couttimeusel;cudaFree(da);cudaFree(db);cudaFree(dc);free(a);free(b);free(c);return0;}编译:
/usr/local/cuda/bin/nvccmain_4.2实践向量相加
编译之后得到可执行文件VectorSumCPU和VectorSumGPU之后,我们可以执行一下比较下运行时间(注意要在linux下运行):
./
(base)wjh19@iccv:~/mage/CUDA/db$./VectorSumGPU10000000001000000000threadPerBlock:256blockPerGrid:39062501.6e-05
GPU对于计算简单,并行度高的计算果然可以大幅提速!!!
(base)wjh19@iccv:~/mage/CUDA/db$./VectorSumCPU100010001e-06
(base)wjh19@iccv:~/mage/CUDA/db$./VectorSumGPU10001000threadPerBlock:256blockPerGrid:41.3e-05
GPU对于少量计算效率反倒不如CPU。
参考
1.深蓝学院课程讲解:
2.,“ProgrammingMassivelyParallelProcessors–AHands-onApproach,SecondEdition”
3.CUDAbyexample,SandersandKandrot
4.NvidiaCUDACProgrammingGuide:
5.CS/EE217GPUArchitectureandProgramming









